
Part 1: Implementation Strategy
Infrastructure as Code (IaC) has become a cornerstone of modern, robust and scalable IT operations. By using IaC, infrastructure is collaboratively managed, consistently tested for compliance as well as being deployed with speed and a high degree of precision. In treating infrastructure as application code, including testing, CI/CD and version control, IaC brings with it reliability, consistency and some form of agility to the management of infrastructure. Following this approach guarantees that there are stable and reusable environments across all possible stages. The approach also enables scaling rapidly and provides a simplified disaster recovery process. Due to this, IaC has impacted the way that businesses view the management and deployment of infrastructure, allowing manual processes to be replaced with automated, code-driven workflows.
In this series of blogs, we will be looking at the following in relation to IaC
- Implementation strategy
- Core concepts
- Detailed Tool Analysis
- Advanced best practices
Initial Setup
We will be making use of VS Code as our IDE and we will be using Terraform for the examples in this section.
Starting off by creating a new Terraform project.
- Download and install Terraform, then add it to your system’s PATH.
- Create your project directory and open it up in your chosen IDE
Within your new project directory, create the following files:
- provider.tf – Specifies the provider configuration
- variables.tf – Defines input variables for configuration.
- main.tf – Contains the main Terraform configuration, such as the VPC, subnets, and other resources.
outputs.tf – Specifies output values, if you want to retrieve information about created resources after deployment.
Your project structure should currently look like this:
The first phase is when the basic essential infrastructure for an environment is created, making sure the environment is reliably functioning. By firstly focusing on foundational resources, we create a stable base that can be used to add more complex components later.
- Network Configuration: Setting up Virtual Private Cloud (VPC) and subnets to establish isolated networks for different environments (e.g., production, development). An example being a single VPC with multiple subnets (e.g., public and private) in a specific AWS region. The following snippets show how to set up a basic network infrastructure on AWS.
provider.tf
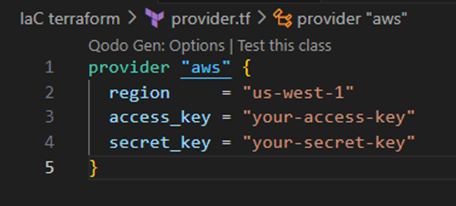
In the provider.tf file, we specify the provider and the region in which the resources will be created. It is possible to add the keys to this file, although it is not recommended, and the more acceptable method would be to set them as environmental variables.
variables.tf
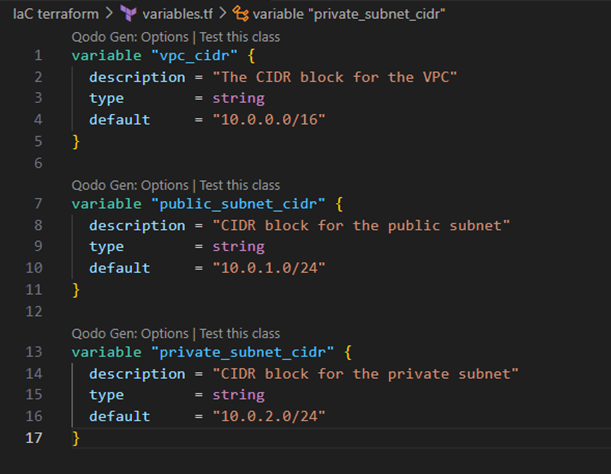
In this file, we define input variables that can be used to make the configuration more flexible. It is defined with a variable name, a description of the variable, the variable type and the default value of the variable.
main.tf
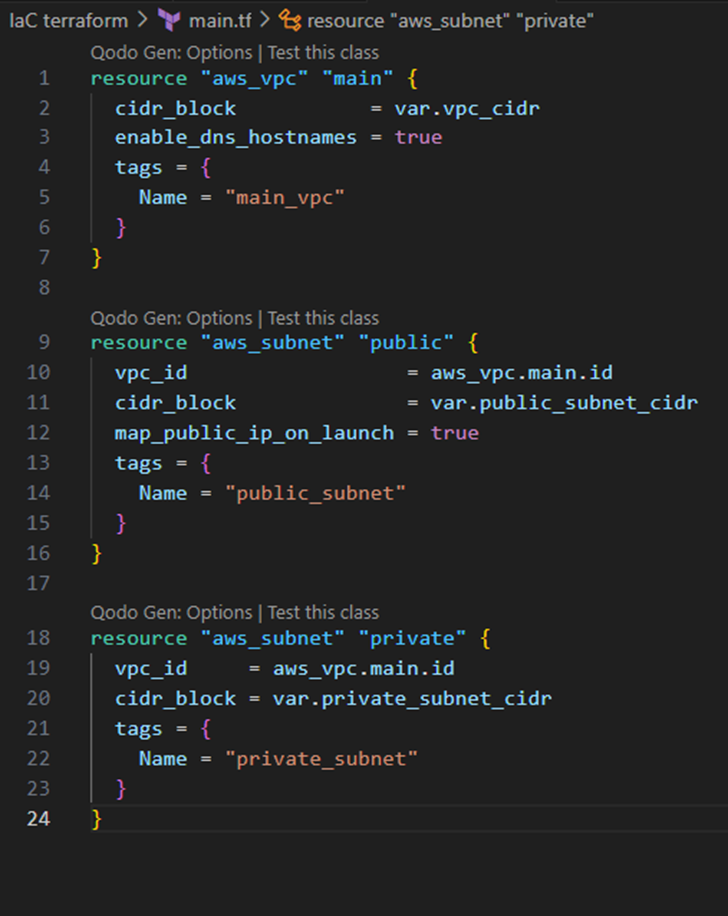
The main.tf file contains the actual configuration for the infrastructure resources.
The above example shows the creation of three resources. The first being a vpc, this is configured with a ‘cidr_block’, the value of which we pull from our variables.tf file. The other two resources being created are private and public subnets, each of which also pull variable information from the variables.tf file, as well as getting the ID of the vpc created above them.
outputs.tf
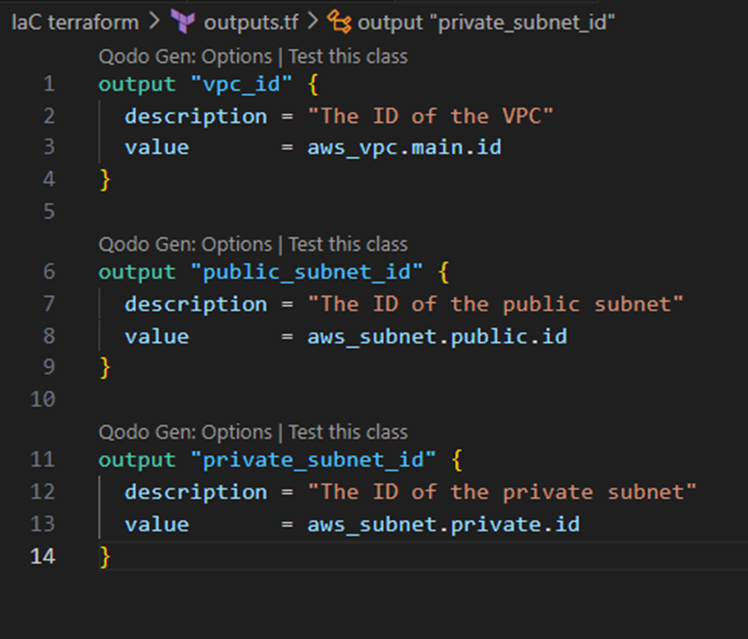
The outputs.tf file allows for output values to be defined, creating an easier method of viewing important resource details after deployment. The above file shows how we define output values for the VPC, the public subnet and the private subnet in order to view the created resources ID’s.
- Security Groups and IAM Roles: Configuring security groups to control network traffic and IAM roles for secure access control. Security groups act as firewalls for instances, while IAM roles define access permissions. The following example shows how to allow HTTP (port 80) access for a web server. For this example, all of the configurations will be done in the main.tf file only.
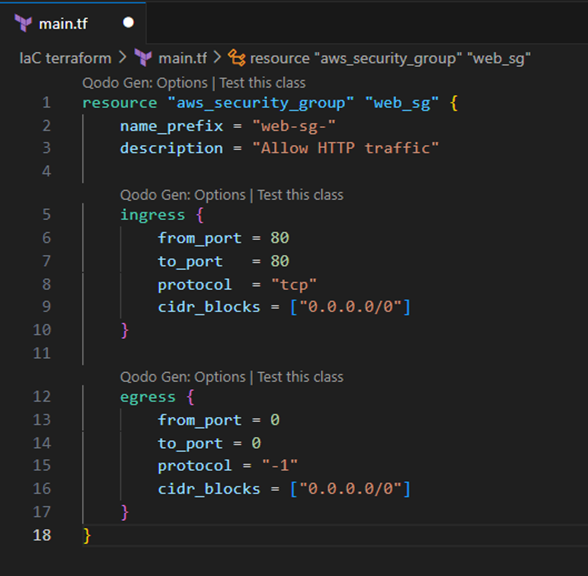
We start by creating the security group as a resource, and we give it the name in terraform of ‘web_sg’.
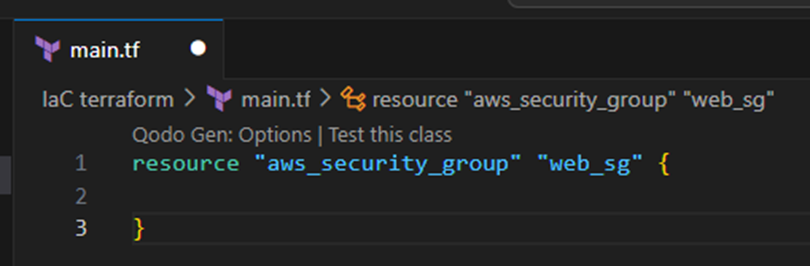
Next, we set the config values for the security groups description and prefix name.
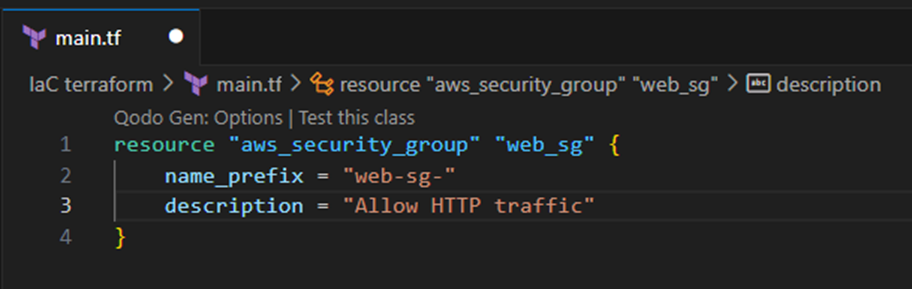
Once this is done, we will then define the rules for incoming traffic allowed into resources within the security group. This process includes using an ‘ingress’ block to define which ports are available to traffic (in this case, default HTTP port 80), the rules protocol (specifically tcp in this case), and finally the cidr_blocks (this case allows for traffic from any publicly accessible IP address.
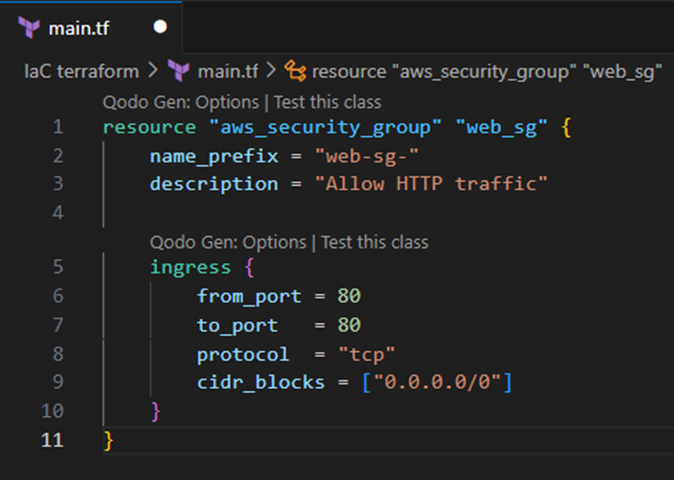
Lastly, we add the ‘egress’ block, which defines the rules for outgoing traffic. In this block, we define the same values as the rules for incoming traffic, but in this instance, our port is set to port: 0, this means all ports are open for outgoing traffic. The protocol is set to ‘-1’, this meaning that all protocols are allowed (e.g. TCP, UDP etc.). And the cidr_blocks can be set to the same value in the ingress block.
- Basic Compute Resources: Deploying essential compute resources (such as EC2 instances for web servers or application servers) configured with proper security and monitoring. For example, Provisioning a basic EC2 instance for a web server.
Let’s start by provisioning an EC2 instance and naming it web_server in terraform.
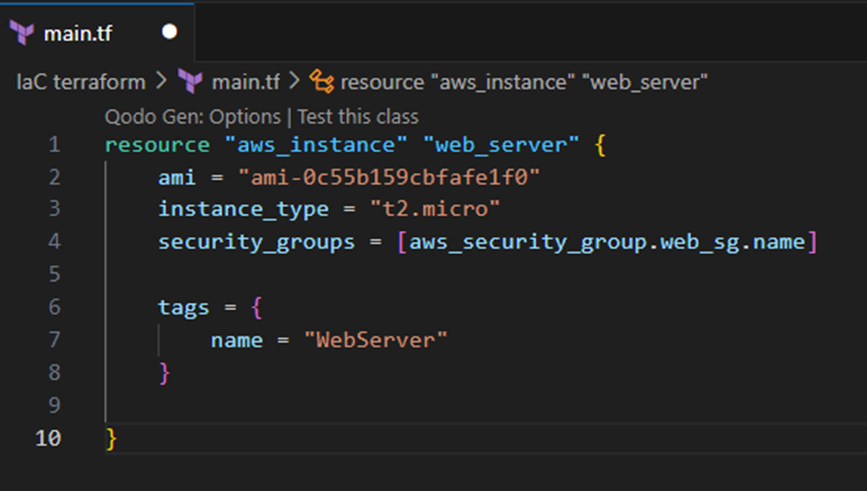
We then specify the AMI (amazon machine image) ID for the instance to use (e.g. the following example ubuntu ID). We also specify the instance type, in this case we use the t2.micro instance type, which is usually suitable for web servers in testing environments and falls part of the AWS free tier. The security group that this instance will use is also specified, in this case we can specify the security group we created earlier. Lastly, we can tag the instance with a name.
Scaling Out
Once the foundational components are in place, the second phase is to scale out the infrastructure. This step usually involves adding resources that improve the environment’s capacity, performance, and resilience.
- Load Balancers and Auto-Scaling Groups: Setting up load balancers to distribute traffic across multiple instances, and auto-scaling groups to dynamically adjust the number of instances based on traffic.
- Database Clusters: Adding database clusters (e.g., RDS for relational databases) for scalable and managed data storage.
- Monitoring and Logging: Setting up monitoring and logging (e.g., CloudWatch or Datadog) to collect and analyse metrics, improving visibility into the health and performance of the infrastructure.
- CI/CD Pipeline Integration: Integrating a CI/CD pipeline for automated code deployment and testing, allowing for streamlined updates.
Advanced Features
In the final phase, advanced features are implemented to improve the resilience, security, compliance, and efficiency of the infrastructure. Some of these features are as follows:
- Multi-Region Deployment involves deploying application resources (e.g., servers, databases, or load balancers) across multiple AWS regions to achieve high availability and disaster recovery. This ensures that even if one region becomes unavailable due to natural disasters, technical outages, or other disruptions, the application remains operational by shifting traffic to another region.
The following example shows an example of a terraform configuration, setting up two load balancers using route 53.
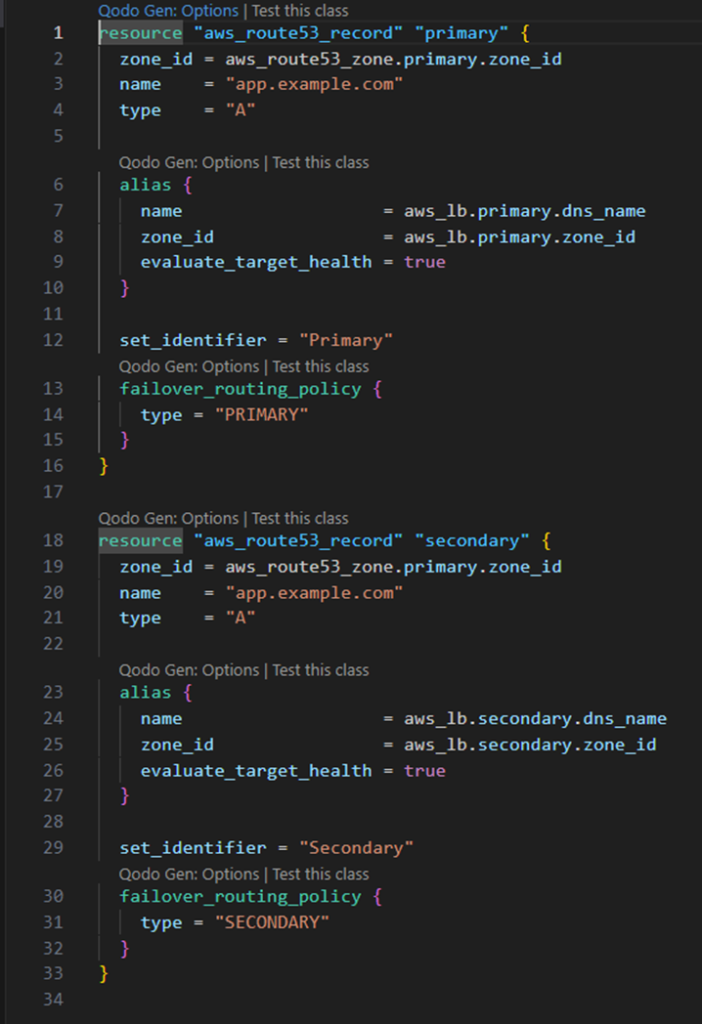
In the example, the Resource blocks create A records in the DNS zone managed by Route 53. It contains a zone_id that specifies the hosted zone, the name which is the subdomain for the application and a type that is used to set the record type.
The alies blocks specifies the target for DNS resolution, linking it to the specified load balancer. The blocks contains the DNS name (name), the hosted zone id (zone_id) as well as evaluate_target_health set to true, which allows Route 53 to monitor the health of the load balancer.
- Disaster Recovery (DR) is the process of preparing for and recovering from system failures, outages, or disasters (natural or man-made) that can disrupt business operations. Effective disaster recovery configurations ensure business continuity, minimize downtime, and protect critical data.
- Compliance and security controls are essential for protecting systems, data, and users while ensuring adherence to legal, regulatory, and organizational standards. Implementing these controls involves applying policies, mechanisms, and tools to mitigate risks, enforce accountability, and meet compliance requirements.
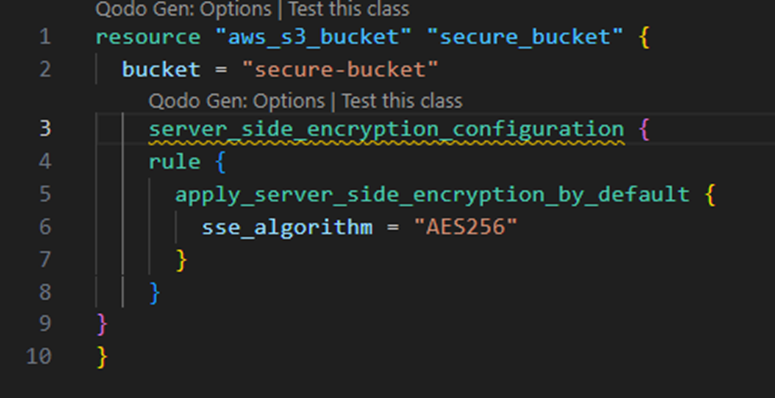
The following example shows the creation of an S3 bucket with server-side encryption enabled. The code contains the resource block, that is made up of the bucket name, and the SSE configuration. The SSE config specifies a rule. The specified rule, being ‘apply_server_side_encryption_by_default’ sets the SSE algorithm as AES256.
- Cost optimization strategies involve implementing practices, tools, and configurations to minimize the cost of cloud resource usage without compromising performance, availability, or scalability. By actively managing and optimizing cloud infrastructure, organizations can achieve significant savings and maintain financial efficiency.
Infrastructure as Code represents a transformative approach to managing and deploying IT infrastructure that brings unprecedented levels of reliability, scalability, and efficiency to modern technological environments. In this first blog of the series we have seen that the journey of implementing IaC typically progresses through three critical phases: establishing foundational infrastructure, scaling out resources, and implementing advanced features. By building out the initial implementation using these phases, it allows businesses to build robust, secure, and adaptable technological ecosystems that can rapidly respond to changing operational requirements. We have made use of tools like Terraform which enable teams to version control their infrastructure, ensure repeatable deployments, and maintain high standards of compliance and security. As cloud technologies continue to evolve, Infrastructure as Code will undoubtedly remain a crucial strategy for businesses seeking to maintain agility, reduce manual errors, and drive technological innovation in an increasingly complex digital landscape.